
Imagine this: a PRI official in Odisha opens a chatbot and sends a voice note in Odia, asking whether a central tap-water scheme applies to his village. The audio hits a speech-to-text model, and half the words come back wrong. The chatbot pulls the wrong policy document. The official walks away with bad information about a scheme that affects thousands of households.
Challenges in governance at the grassroots level are often linked to limited capacity and support for Panchayati Raj Institution (PRI) officials. To address this gap, the CBC project aims to strengthen the capacity of PRI officials and elected representatives by providing them with accessible, reliable information that helps them effectively utilize local governance structures to drive grassroots development.
Thus, a chatbot designed to help Panchayat officials is planned to roll out across four states—Andhra Pradesh, Gujarat, Assam, and Odisha—and will support multiple languages, including Hindi, English, Assamese, Gujarati, Odia, and Telugu. Here, transcription accuracy is critical; a poor transcription is not just a technical glitch but a potential source of misinformation at the governance level.
This is the problem we set out to solve. We benchmarked 7 speech-to-text models across 3 Indian languages, identified the best option for production, and integrated a reusable STT evaluation framework into Kaapi so NGOs can make data-driven decisions about voice AI rather than guess. This blog walks you through what we found and what we shipped.
(This is a follow-up to our earlier post on AI Evaluation: From “Seems Good” to “Scores Good”, which covered text-based evaluation.)
Why This Matters Now
Since launching text-based AI evaluation, NGOs like ATREE, SEARCH, and Antara have been using it to test new models and prompts before deploying them to their communities. The natural next step: extend this to multi-modal to serve even greater usecases and communities
Two years ago, we added speech-to-text and text-to-speech support in Glific to serve communities that prefer audio over text.
Read more: Enhancing Communication with AI and Text-to-Speech in Glific
Back then, we started with OpenAI Whisper models but quickly found that its models struggled with Indic languages — simply not enough training data. We moved to Bhashini, which worked better for Hindi and other Indic languages
But the landscape has shifted. New models from Google, Sarvam, ElevenLabs, and AI4Bharat now claim strong Indic language support. There are just so many options now than there were 2 years ago, but before jumping to the next shiny model, we needed to answer a simple question: which one actually works?
The ‘R’ in R&D: What we found
Before we jump into development, we set out to do some initial research to determine which STT models perform best for Hindi, Assamese (Axomiya), and Odia — measured by Word Error Rate (WER), which is the percentage of words the AI gets wrong compared to the actual transcript. We also used a custom Lenient WER that forgives phonetically equivalent Indic script variations (like matra or chandrabindu differences).
We benchmarked 7 models — Gemini-2.5-pro, Gemini-2.5-Flash, Chirp 3 (Google), GPT-4o-transcribe (OpenAI), Scribe_v2 (ElevenLabs), Saaras:v3 (Sarvam), and Indic-conformer-600m-multilingual (AI4Bharat) — against ~95 annotated audio-transcript pairs across three languages. All models were tested via API except AI4Bharat, which required a self-hosted GPU endpoint.
Top 3 per language (Avg WER %):



Why We Went with Gemini-2.5-Pro
AI4Bharat edges ahead on raw accuracy, winning 2 out of 3 languages. But the top 3 models in each language are close, with differences being marginal. Gemini-2.5-Pro stood out as the practical production choice:
- API-first, zero infra — just an API call. No self-hosted GPUs like AI4Bharat requires.
- Steerable and versatile — Can be prompt-engineered to do transcription and translation to English in a single step without special mode keys.
- Consistent results — Unlike GPT-4o-transcribe (flaky WER across runs) or Gemini-2.5-Flash (WER swung from 53% to 34%), it delivers stable, deterministic outputs.
- Solid all-rounder — Ranks in the top 3 across all three languages, with no language-specific setup needed.
The trade-off: ~2x higher latency than Sarvam or ElevenLabs — acceptable given the steerability and operational simplicity.
Limitations worth noting: Sample sizes were small (~20-50 pairs per language) and may introduce statistical bias, and lenient WER is an experimental metric applicable to Hindi only.
The ‘D’ in R&D — What We Built
With a clear winner from the research, we built STT evaluation as a first-class feature in Kaapi. Here’s how it works:
1. Upload audio files (mp3, wav, flac, m4a, ogg, and webm) directly through Kaapi; these are stored securely in S3.
2. Create an evaluation dataset. Bundle your uploaded audio files into a named dataset, with each sample paired with an optional ground-truth transcription — the correct transcript you want the AI to match against.
3. Run batch evaluation: Start an evaluation run against your dataset. Kaapi sends all audio samples to the STT model (Gemini 2.5 Pro to start) via an asynchronous batch pipeline — no waiting around. A background job polls for results and processes them as they come in.
4. Get automated metrics: Once transcriptions are back, Kaapi automatically computes four metrics for every sample that has a ground-truth transcription:
- WER (Word Error Rate) — word-level accuracy, the industry standard
- CER (Character Error Rate) — character-level accuracy, useful for catching smaller errors
- Lenient WER — WER after script-aware normalization that handles Unicode inconsistencies in Indic scripts (e.g., matra or chandrabindu variations)
- WIP (Word Information Preserved) — the proportion of correctly recognized words, giving a complementary view to error-based metrics
Per-sample scores are aggregated into a run-level score, so you can see both the big picture and drill into individual results.
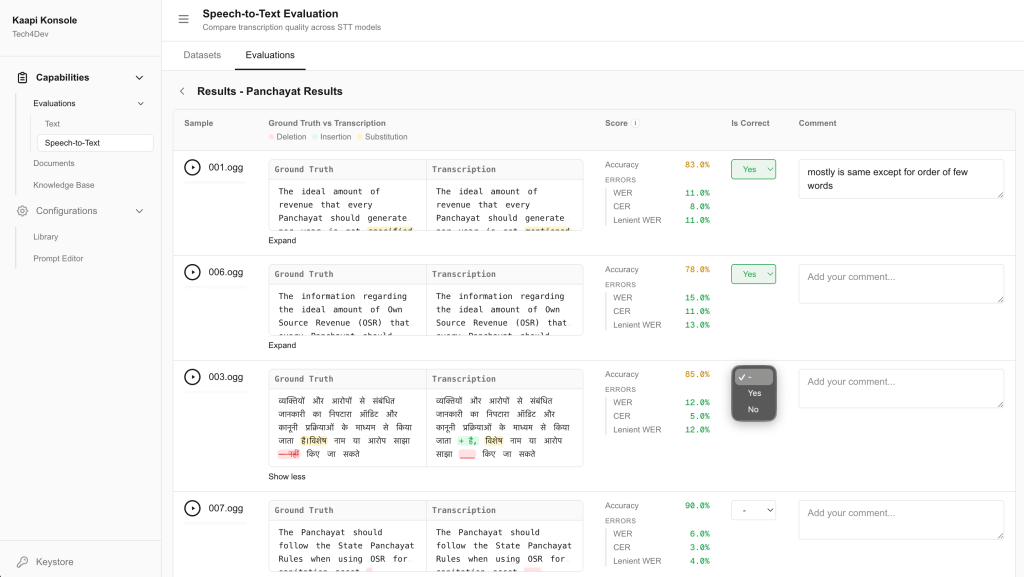
5. Human review Automated metrics don’t capture everything — a transcription might be technically “wrong” by one word but perfectly usable, or technically “right” but miss the intent. Reviewers can listen to the audio, compare it to the AI transcription, and mark each result as correct or incorrect with an optional comment.
The entire workflow is designed so that teams can upload a dataset, hit evaluate, and have concrete numbers within minutes through a simple UI.
The Starting Line, Not the Finish Line
This is the basic scaffolding for STT evaluation. With the core pipeline in place, the next step is adding more providers and models – Sarvam, ElevenLabs, AI4Bharat, and others — so that organizations can compare options and pick the one that works best for their sector, use case, and language.
That said, we should be honest about who will actually use this. Most NGOs won’t run STT evaluations themselves — and that’s fine. For the teams on the ground, what matters is whether the beneficiary’s voice note gets the right answer back. STT is invisible plumbing. It sits in the middle of an interaction where a beneficiary sends an audio message, the system transcribes it, and the transcription is used to pull a relevant answer from AI. NGOs care about that final answer, not the transcription step in between.
Where STT evaluation becomes valuable is when things go wrong — when answers start coming back incorrectly, and the team needs to diagnose whether the problem is the transcription, the AI, or both. It’s also a tool our team uses when working closely with NGO partners to recommend the best model configuration for their context.
And while this fixes one half of the voice-to-voice loop — understanding what the beneficiary said — the other half is how the AI speaks back. TTS (text-to-speech) evaluation is next, completing the full cycle of voice quality measurement.
What’s Next
We went from “which model should we use?” to having a data-backed answer, a live evaluation framework, and automated metrics that score transcription quality with automated metrics and can be manually annotated as well. STT covers the first half of the voice loop — understanding what the beneficiary said. Now we’re working on TTS (text-to-speech) evaluation to close the other half: how natural, accurate, and intelligible the AI sounds when it speaks back.
As we expand to more Indic languages like Marathi, Tamil, Telugu, and Bengali, the goal stays the same – that a PRI official in Odisha shouldn’t get the wrong answer because the AI misheard his question, and the answer he hears back should sound right too. Projects like CBC won’t have to hope their voice AI works across states and languages — they can measure it, compare it, and choose what actually performs.

