
Chatbots can be smarter when they understand how to handle various types of messages automatically. In our conversations with a few NGOs using Glific, one theme consistently emerged: they want to categorise incoming messages to their Glific WhatsApp bots into a predefined set of categories, allowing the chatbot to efficiently route users to the relevant information. At Kaapi, we’ve been working on a fine-tuning pipeline for a classification feature. In simple terms, this means we create a fine-tuned model and then use that model to classify incoming messages. Over time, as the model learns from more data, it gets better at categorising messages and making conversation flows smoother.
1. What is fine-tuning & why do we need it
Think of fine-tuning as teaching an already talented student a new trick. Large language models (LLMs) like GPT-4 know a lot out of the box, but they’re generalists. Fine-tuning takes that base model and feeds it lots of examples for a specific task—like labelling user input as either a question or small talk.
Why bother? Because prompting alone has limits. If you keep telling a model “classify this as a query or small talk” in every prompt, results will vary, especially with short inputs like “hello” or “thanks.” Fine-tuning bakes the task into the model’s DNA, so it learns from thousands of examples and becomes much more consistent.
2. The problem we’re solving
Take the example of SNEHA, an NGO that has been using Glific to run WhatsApp chatbots for maternal and child health for past 2 years. Their users often send sensitive, practical questions like:
- “Mujhe apne 9 mahine ke bachche ko kya khilana chahiye??”
- “Mere bacche ko zukhaam hai, main kya karun?”
But mixed in with these are everyday chit-chat messages:
- “Hello!”
- “Thanks 👍”
If the bot sends every message—including small talk—to the question-answering LLM, things get messy. The LLM wastes tokens trying to answer non-questions, sometimes making awkward or confusing replies.

For SNEHA, accuracy is critical. When the question is about child health, the system must respond with clarity and relevance. Fine-tuning helps here: by training a model specifically to recognize what’s a real question versus casual small talk, we reduce noise, cut down token costs, and make the chatbot experience smoother
So the problem statement was simple: can we automatically filter out “small talk” and only forward valid questions to the LLM?
3. Earlier research: semantic routing & fine-tuning
We started by experimenting with two approaches:
- Semantic Routing – an open-source framework that builds a lightweight classifier on top of embeddings. It’s fast, simple, and works well for smaller datasets.
- Fine-tuned LLMs – using OpenAI’s fine-tuning API to train a custom model (in our case, based on GPT-4o-mini).
This data came from chatbot conversations through Glific—around 2,600 examples after filtering out images and audio. Roughly 15% of them were “small talk”. We trained both approaches and compared them
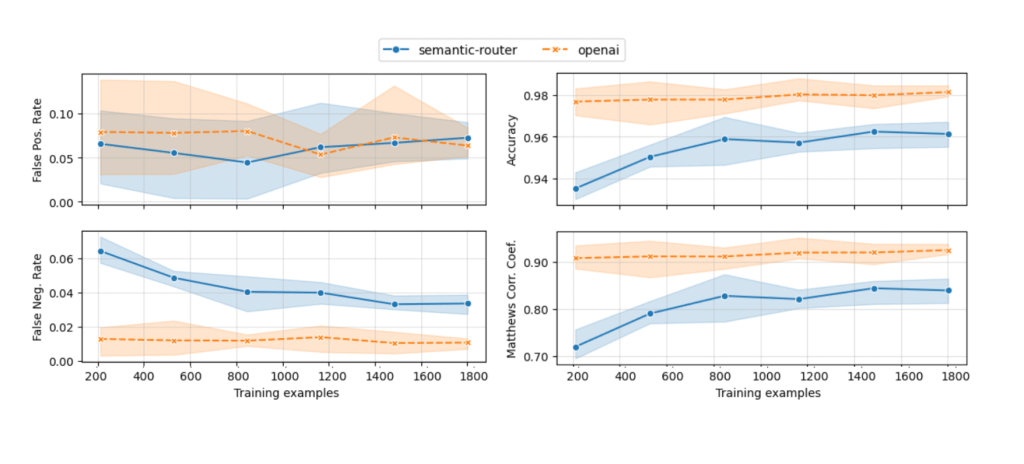
Fine-tuned models were consistently more accurate, especially as the training set grew. Semantic routing was quicker on response time, but it tripped up more often. False positives (sending “hello” as if it were a real question) showed up in both, though at a low rate. If accuracy matters, fine-tuning is the safer bet. If you just need something light and fast, routing does the job
4. Metrics & evaluation
For Version 1 of Kaapi’s classification feature, we kept things simple. Here’s how it works

- Upload data
You start by uploading an annotated dataset CSV with questions and labels (e.g. query or small talk), plus one or more split ratios (say 0.6, 0.7, 0.9). A split ratio decides how much of your data goes into the training set versus the testing set. For example, 0.8 means 80% of the rows train the model, while 20% are saved for testing. - Train multiple models
For each split ratio, we fine-tune a separate model. So if three split ratios (0.5, 0.7, and 0.9) are passed, then three different models are fine-tuned. This is to ensure a fine-tuned model is not overfitting. - Split the data and evaluate
Each split is done with stratified sampling, which keeps the same label balance in both training and testing (about 85% queries, 15% small talk). Without this, you could end up with a test set full of small talk, which would make evaluation meaningless.
Once the model is trained, it’s tested against the testing set. Predictions are compared to the ground truth in the annotated dataset CSV - Score the models
The main metric is the Matthews Correlation Coefficient (MCC). Accuracy alone would be misleading here — a dumb model that always predicts query would score 85% because that’s the label balance. MCC fixes this by weighing true/false positives and negatives into one number between –1 and +1. - Pick the winner
After evaluation, we save the results in database. Through an endpoint, you can call the API to fetch the best model for a given dataset — ranked by MCC — and use it as the default classifier.
.
5. How we move forward
The current version (v1) of classification is already in Kaapi’s production. It works, but it’s just the start. Here’s what’s next:
- Support for more categories: Right now, we do binary classification (e.g. query vs small talk). Future bots may need multiple labels (e.g., question, feedback, complaint, chit-chat).
- Smarter evaluation: We rely on Matthews Correlation Coefficient (MCC), which is great for imbalanced datasets. But NGOs and partners might care about different evaluation metrics depending on their use case.
- Updating models on the fly: When a client provides a new labeled dataset, how do we retrain or update existing models without starting from scratch? That’s a big one on our roadmap.
- Guardrails: NGOs often operate in sensitive domains like healthcare, gender rights, or mental health. Misclassification here can have serious consequences. We’re working on building responsible AI guardrails, so models know when not to answer, and can escalate sensitive inputs to a human or a safer fallback flow.
- Seamless integration into Glific flows: the real power of classification is when it fits naturally into existing NGO chatbot workflows. By embedding classification as a node in Glific, NGOs can just drag-and-drop the classification step into their existing flows
In short, the goal is to make classification flexible, reliable, and simple for organizations to plug into their workflows.
Wrapping up
Small talk works between people. For chatbots, it’s just noise. Fine-tuning helps cut through that noise and keeps bots focused on what matters: real questions from real users. That makes answers sharper, costs lower, and conversations smoother. And like the bots, we’re learning, iterating, and developing with every message
