
Quantitative data is a strong focus for many data wrangling platforms. If you have numeric or categorical data, these tools make it easy to derive insights, make reports, and drive decision making that is objective. Qualitative data, while just as informative, hasn?t been so lucky. Until recently has been a lot tougher to work with and subsequently snubbed in many data workflows. The development and accessibility of large language models is changing that narrative, and Dalgo is racing to take advantage.
A perfect example is a feature we?re building to help make sense of qualitative data organized by qualitative features. This blog post presents a recent use case we?ve developed with STiR Education that shows what we mean.
Motivation: the STiR use case
STiR Education supports government education systems to reignite intrinsic motivation, so that every official, teacher, and child is motivated to learn and improve. Transcriptions of these activities produce reams of free form qualitative data. To properly archive the information, there is a rich set of quantitative data that lives alongside it: the event type, when and where it occurred, and the persons involved, for example. Since these aspects also describe other STiR activities, the qualitative data fits right into existing relational schemas. Unfortunately, SQL?s string operations are too rudimentary to make the relationships meaningful.
What STiR wanted was to get a sense for themes and summaries across these qualitative activities, differentiated by one or more of their traits. The sentiment of teacher feedback per location over the last month, for example. To accomplish this, their evaluation team developed a manual process involving ChatGPT. They would first filter teacher conversations based on quantifiable information ? when and where the conversation took place, for example ? then copy only the remarks from that filtering. The remarks would be pasted into a ChatGPT session, along with a short instruction prompt asking the LLM to summarize the data in various ways. In addition to summarization, they requested strict output formatting to ensure the response was directly usable in their regular reporting presentations.
This was the perfect use case for LLMs, since they are really good at natural language processing. This was also a perfect use case for Dalgo, since it?s really good at data. What a time to be alive!
Building the POC
Our first step was to better understand STiR?s manual process ? what qualtitative data they were using, how it was being filtered, and how it related to the quantitative components. Because STiR is a Dalgo user, it was straightforward to turn these lessons into aggregation and transformation pipelines. We had a structured candidate table in a matter of minutes. From this table, we were able to run simple SQL statements that selected qualitative data filtered by quantitative columns.
Our next step was to better understand how the evaluation team used ChatGPT. What insights were they trying to get from the qualitative remarks, how did they express this desire to the LLM, and how satisfied were they with the result. This allowed us not only to replicate their work ? to the extent possible with LLMs ? but also to have a point of comparison as we developed our own prompts.
Those pieces were stitched together using Open AI?s GPT API. Quick and painless for a seasoned engineer.
With a working end-to-end system, we needed a user interface. Ideally, this would live inside Dalgo, but in the spirit of quick iteration we built something using Gradio. Gradio has great support for building chatbot interfaces, handling all the messy Javascript required to make a web application reliable and reactive. We could focus entirely on exposing our prior effort. The following image shows the landing page of our web app:
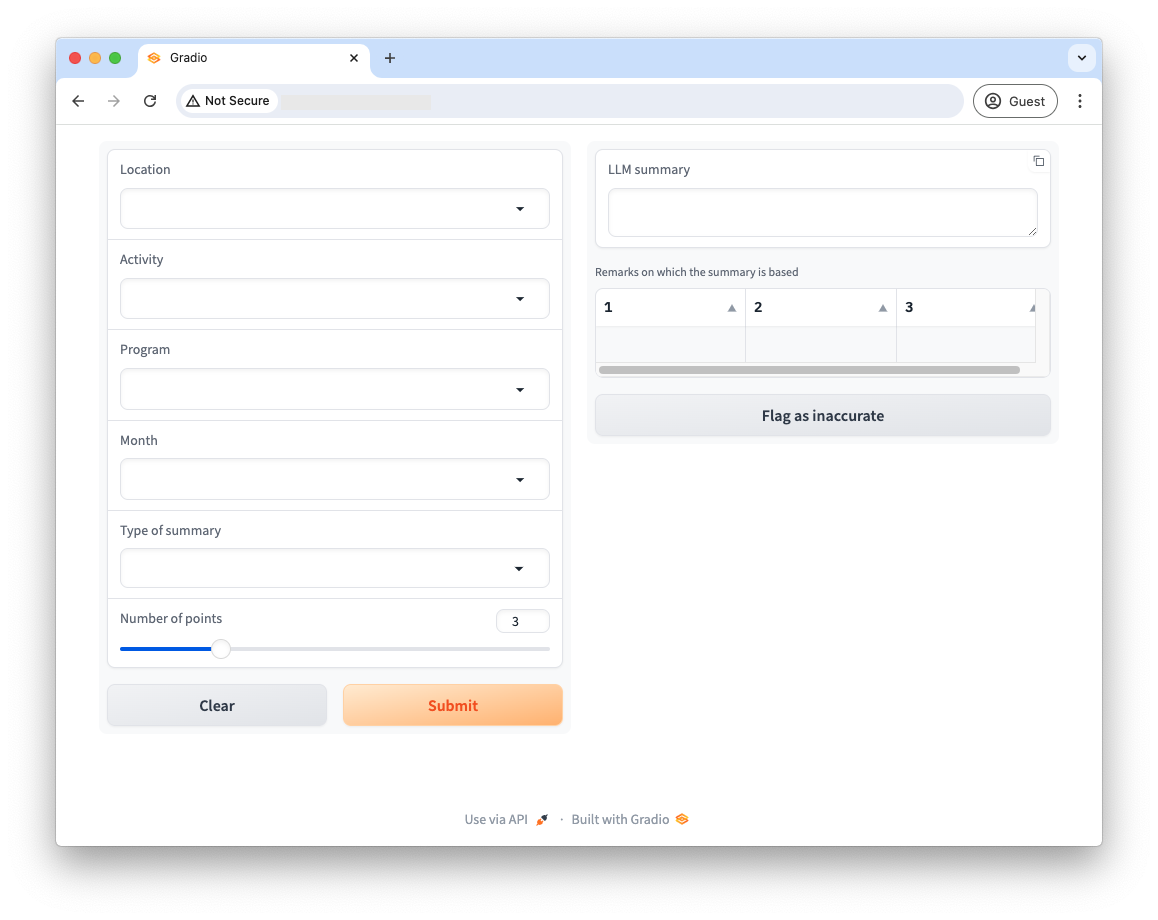
The interface is divided into two halves. On the left are facets by which users can filter underlying qualitative data. Toward the bottom, there are options that affect prompt generation: ?type of summary? and ?number of points.? The qualitative data in this case was feedback from teachers about the STiR programming they received. To that end, summary types could either be best practices STiR conducted, or areas of improvement. The LLM is asked to summarize remarks into a discrete number of points ? that number is specified with the slider.
The right side is populated after selections are made and ?submit? is clicked. Submission first generates an SQL query, then issues that query to the database tables in Dalgo. The returned qualitative data is inserted into an appropriate prompt, and the package is sent to Open AI. The model’s response is presented to the user in the ?LLM summary? box. There is a copy button in the upper-right corner of that field making it easy to copy-paste results wherever required. The table below the summary is filled with the remarks selected by the SQL statement. While that data is not generated by the LLM, displaying it allows users to validate the generated summary.
Future
STiR has been a great partner to work with on this. They have found the tool useful, and have offered feedback that will make it even better for future organizations.
While Gradio has been great as a prototyping mechanism, getting this functionality natively into Dalgo is the way forward. The Dalgo team is now busy integrating the tools programmatic logic into the platform and thinking through interface designs that fit nicely into the existing user experience.
It?s about time qualitative data was promoted, accessible, and valued. We?re excited for this feature to be a step in that direction.